|



Суммирование последовательности чисел
1. Параллельная программа
Рассмотрим нахождение суммы последовательных чисел
Y = 1 + 2 + 3 + … + k
Для удобства проверки будем считать, что количество чисел k четное. В этом случае легко заранее получить ответ, сгруппировав числа попарно: первое число с последним, второе – с предпоследним и т.д. В итоге одинаковые суммы всех пар достаточно умножить на их количество
Y = (k+1)*k/2
Пусть для определенности k = 24, а сумму вычисляют четыре ПУ с номерами от 1 до 4. Чтобы построить параллельный алгоритм, достаточно разбить всю сумму на равные части по 24/4 = 6 слагаемых. В результате ПУ1 просуммирует числа 1-6, ПУ2 – 7-12, ПУ3 – 13-18 и ПУ4 – 19-24. Если принять, что программа во всех ПУ одинакова, то тогда исходное значение k0 для старта суммирования (равное 0, 6, 12 или 18) должно передаваться извне.
В итоге для ПУ1-ПУ4 получим следующую программу суммирования 6 чисел (для экономии места она записана в строку; о правилах записи программ в файл см. здесь):
i M0 1 M+ 1 M+ 1 M+ 1 M+ 1 M+ 1 M+ MR o
Программа начинается с приема k0 командой i и очистки памяти (занесение туда нуля) командой M0. Далее 6 раз повторяется пара команд 1 и M+, которые увеличивают текущее значение числа на 1 и прибавляют полученное новое число к содержимому памяти. Итоговая сумма считывается из памяти по команде MR и возвращается в ПУ0 командой o.
Прмечание. А лучше было бы команду M0 оставить перед i!
Роль главного Удвоителя ПУ0 состоит в распределении работы и сборе ответов:
R o1 R o2 R o3 R o4 i1 A2 A3 A4 W
Он читает нужные значения k0 с помощью команды R и по очереди передает их в ПУ1-ПУ4 командами o1-o4. Далее он принимает первую сумму командой i1, а затем команды A2-A4 прибавляют к ней остальные три части суммы. Последняя команда W служит для вывода результата.
2. Выполнение программы
Очень интересно построить временную диаграмму выполнения всех параллельных программ. Главная трудность здесь заключается в том, что надо постоянно следить за тем, что разные команды выполняются за разное время – за разное число тактов.
В первой строке указаны номера тактов работы системы (от 1 до 39). Программы для каждого ПУ располагаются в следующих строках таблицы слева направо. Цветом выделены команды обмена. Благодаря этому легко можно нацти, какие ПУ обмениваются данными. Например, видно, что в такте 10 завершается передача числа из ПУ0 в ПУ2, а в такте 22 - из ПУ1 в ПУ0.
| такт | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ПУ0 | R | o1 | R | o2 | R | o3 | R | o4 | i1 | ждет | A2 | ждет | A3 | ждет | A4 | W | |||||||||||||||||||||||
| ПУ1 | ждет | i | M0 | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | MR | o | ||||||||||||||||||||||
| ПУ2 | ждет | i | M0 | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | MR | o | ||||||||||||||||||||||
| ПУ3 | ждет | i | M0 | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | MR | o | ||||||||||||||||||||||
| ПУ4 | ждет | i | M0 | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | 1 | M+ | MR | o | ||||||||||||||||||||||
Разберем эту сложную таблицу подробнее.
Сначала взглянем на вторую строку, которая соответствует главному Удвоителю ПУ0. Он читает начальные значения k0 и передает их в ПУ1-ПУ4. После этого происходит переход к приему результатов с одновременным суммированием их. Программа завершается выводом итоговой суммы на экран.
Посмотрим, что делают в это время периферийные ПУ. Каждый из них начинает с того, что (в порядке очереди) принимает свое начальное значение для суммирования. Ожидание ввода начинается с момента старта, поэтому все ячейки таблицы закрашены от начала строки (ожидание обмена – это тоже часть обмена!) Кстати говоря, из таблицы отчетливо видно, что ПУ1 ждет наименьшее время, а максимум ожидания приходится на ПУ4.
Далее начинаются вычисления. Каждая вычислительная команда (1, M+ и другие) выполняется за один такт. В то же время ПУ0 выполняет двух- или трехтактовые команды R, o и другие. Напомним, что количество тактов, которое требуется для каждой команды, можно определить из таблиц.
Завершив вычисления, ПУ1 возвращает результат в ПУ0. Анализ таблицы показывает, что когда ПУ0 доходит до команды ввода, результат в ПУ1 уже готов (см. такт 21 в таблице). Зато для ПУ2-ПУ4 это не так. Скажем, в тот момент, когда ПУ0 выходит на команду A2, ответ в ПУ2 еще не сосчитан. Следовательно, управляющему ПУ приходится ждать (об этом говорит появление дополнительных закрашенных ячеек - такты 23-25, в строке для ПУ0).
3. Когда есть эффект от параллельных вычислений?
Поставим вопрос: как влияет на общее время то, насколько быстро периферийные ПУ вычисляют результат? Очевидно, что полезная работа для нашего параллельного исполнителя – это вычисления. Оценим, какую часть времени любой из ПУ1-ПУ4 непосредственно занят вычислениями. Время счета для каждого ПУ получить несложно: для этого достаточно подсчитать количество вычислительных команд в одной из строк приведенной выше таблицы. Таких команд оказывается 14 (i и o не берем, так что по сути дела просто считаем "белые" ячейки!) Каждая из них выполняется за один такт, поэтому время вычислительной работы для Удвоителя в данной задаче составляет 14 тактов. Полное решение задачи получается за 39 тактов. Следовательно, время полезной работы (счета) для каждого из ПУ1-ПУ4 составляет примерно 36%.
Кроме того, если проанализировать таблицу по столбцам, то мы с удивлением обнаружим, что нет ни одного(!) столбца, где бы стояли только вычислительные команды - когда ПУ4 начинает, наконец, вычисления, ПУ1 их уже закончил. Иными словами, в данном конкретном случае ни разу все четыре ПУ не выполняли вычислений одновременно.
Напрашивается вывод о том, что наш вычислительный исполнитель загружен слабо. Как это можно исправить? Рецепт прост: надо взять больше чисел, т.е. увеличить значение k. Если не менять при этом число ПУ, то количество обменов данными останется прежним, зато количество вычислений возрастет. Например, эксперимент с программной реализацией исполнителя при k = 120 дает такие результаты: количество тактов вычислений – 62, а полное время работы программы – 87 тактов. Отсюда следует, что коэффициент полезного действия нашего исполнителя возрастает до 71%, т.е. практически вдвое. А это значит, что при большом объеме параллельные вычисления действительно могут быть полезны.
4. Мера ускорения вычислений
Традиционной и очень наглядной мерой ускорения параллельных вычислений служит величина
где T1 - это время выполнения программы на одном вычислительном устройстве, а Tp - время выполнения программы на параллельной машине с p устройствами. Имея в своем распоряжении программную реализацию нашей системы из параллельных удвоителей мы легко можем измерить оба значения времени (точнее, количество тактов, затраченное на полное выполнение программы) и высчитать их отношение. Параллельная программа уже написана выше. Что касается программы для одного ПУ, то она будет выглядеть так:
0 M0 1 M+ ... (пара команд 1 и M+ повторяется 24 раза) ... MR W o
Время ее выпполнения на ПУ0 и будет T1.
Ускорение вычислений S как функция количества ПУ p при нескольких фиксированных значениях количества суммируемых чисел k приведены на следующем рисунке.
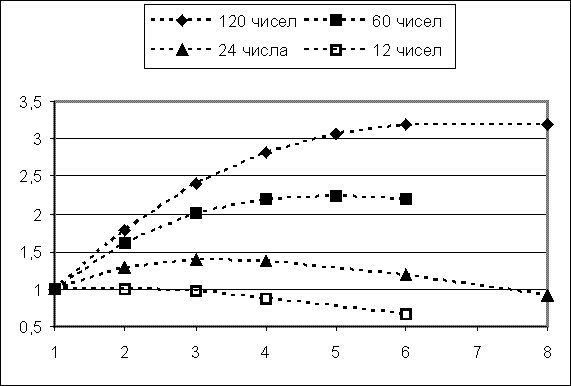
Отчетливо видно, что чем больший объем вычислений приходится на один Удвоитель, тем лучше. Нижняя кривая, для которой k = 12, вообще целиком лежит ниже единицы, т.е. получить здесь какое-либо ускорение не удается вовсе; причем, чем больше ПУ мы берем, тем хуже ситуация. Такое поведение на первый взгляд, необычно, но если мы вспомним, что на одного исполнителя приходится k/p чисел, то все становится на свои места. Так в случае k = 12 и p = 6 каждый ПУ обсчитывает всего по 2 числа.
Напротив, если взять k = 120, то ускорение окажется вполне ощутимым – до трех раз при p = 8. Заметим, что для больших p оно все равно начнет падать из-за роста количества тактов обмена.
Дополнительно был опробован еще один вариант параллельного алгоритма суммирования: начальные значения для каждого ПУ не передавались из ПУ0, а вычислялись в каждом ПУ по своей программе. Удаление передачи входных параметров позволило для некоторых значений получить небольшой выигрыш (например, при p = 4 потребовалось 80 тактов вместо 87).
А теперь покажем другой полезный метод анализа результатов для нашей вычислительной системы S9PU. Выведем аналитические формулы, описывающие ускорение S как функцию p и k, т.е. фактически формулы для пунктирных кривых на приведенном выше рисунке, который был построен табличным процессором Excel.
Предварительно получим выражение для вычисления всей суммы на ПУ0 – для «однопроцессорного» алгоритма. Считается общее количество тактов достаточно быстро: 2 подготовительных такта (команды 0 и M0), k раз по 2 команды для суммирования каждого числа и 3 такта на вывод (MR и W). Итого тактов
Перейдем к параллельным вычислениям.
1 случай – «легкие» приложения: объем вычислений в каждом ПУ так мал (подчеркнем, это означает маленькое значение k!), что основное время занимает «раздача» исходных значений из ПУ0 и обратный прием результатов. В такой ситуации время работы полностью определяется командами программы для ПУ0. Их длительность легко подсчитать по листингу. При этом никаких ожиданий, естественно, не будет, поскольку вычисления в ПУ выполняются очень быстро.
Вывод формулы необычайно прост. Для каждого ПУ выполняются команды R, i и o, суммарное время которых при отсутствии ожиданий равняется 7 тактов. Не забыв добавить 2 такта на команду вывода ответа W, окончательно получаем время для параллельного алгоритма
Ускорение от применения параллельных вычислений
Формула простая, но не очень интересная для практики: она, по сути, описывает график падения S при больших p. Более важен другой случай.
2 случай – «тяжелые» приложения: объем вычислений в каждом ПУ велик (большие значения k). В этой ситуации надо считать время по последнему ПУ. Он стартует после p команд R и o (см. параллельную программу для ПУ0 и таблицу потактового выполнения программы). Таким образом, до старта проходит 5p тактов. Затем следуют вычисления в последнем ПУ: по 2 такта на каждое из k/p слагаемых. Еще 3 такта уходит на вывод суммы командой o. Наконец, мы пока не учли команды M0, MR в этом ПУ и вывод окончательного ответа на экран W в ПУ0 - все они добавляют к общему времени еще 4 такта. В итоге полное число тактов
Все точки на приведенном рисунке, кроме одной (самой неинтересной с k = 12 и p = 6) в точности совпадают со значениями, которые дает выведенная формула.
Полученная формула позволяет оценить всевозможные зависимости, не проводя вычислений на S9PU; например, легко построить график S(k) для нескольких p. Можно убедиться, что при больших k график стремится к значению p.
© Е.А.Еремин, 2017
