|



Об образовательных возможностях Debug
(переход к другим статьям из этой серии)
3. Как процессор обменивается данными с памятью
Способы задания адреса в командах и соответствующие механизмы доступа к ячей-
кам памяти составляют важную часть архитектуры компьютера – систему адресации.
Н.П. Бруснецов [1]
Существует много других режимов адресации, с некоторыми из
них мы столкнемся позже, но большая их часть нам не понадобится.
П. Нортон [2]
Мы уже отмечали ранее, что данная серия публикаций по работе с отладчиком Debug была задумана как продолжение статьи [3], в которой речь шла о демонстрации в курсе информатики приемов работы с регистрами процессора. Поэтому вполне логично, что один из выпусков (а именно сегодняшний) будет посвящен изучению с помощью Debug способов записи и чтения данных, находящихся в памяти компьютера.
Лишь очень небольшое количество данных может быть обработано внутренними средствами процессора с помощью его немногочисленных регистров. Большая же часть сколько-нибудь реальных задач требует запоминания данных, а часто и некоторых промежуточных результатов, в памяти. Поэтому способы обмена информацией с памятью являются одной из важнейших черт внутреннего устройства компьютера.
Особо хочется подчеркнуть, что разобраться с базовыми принципами адресации памяти полезно не только с позиций понимания внутреннего устройства компьютера и взаимодействия его блоков. Данный материал имеет самую непосредственную связь с принципами хранения различных структур данных; в частности, в этом выпуске будет подробно показано, как в памяти организуются одномерные и двумерные массивы и как с помощью различных методов адресации осуществляется доступ к элементам этих массивов.
Для того чтобы картина адресации в современных компьютерах была ближе к реальности, в статье также рассмотрены наиболее важные принципы доступа к памяти в многозадачном режиме. К сожалению, этот материал не удается проверить с помощью каких-либо экспериментов в Debug, поскольку операционная система скрывает от прикладного программиста свои внутренние механизмы адресации.
Несмотря на обилие литературы по описываемой теме, увидеть за многочисленными техническим подробностями наиболее важные положения не так просто. По мнению автора, именно внимательная «очистка» от второстепенных деталей и выделение главного делает публикацию оригинальной, отличает ее от уже существующих. Все подтверждающие теорию эксперименты разработаны специально для статьи, что также усиливает ее «нереферативный» характер. Автор искренне надеется, что публикуемые материалы будут полезны широкому кругу читателей, которые задумываются над тем, каким образом современный процессор находит в памяти нужную информацию.
3.1. Краткие сведения об устройстве памяти
Каждому, кто изучал хотя бы минимальный курс информатики, известно, что все данные и программы их обработки хранятся в компьютере в дискретном двоичном виде. Согласно классическим принципам, минимальной допустимой информацией является 1 бит и именно бит служит основой компьютерной памяти, ее минимальным конструктивным элементом. В старых ЭВМ бит можно было в полном смысле слова увидеть или потрогать руками (см., например, фотографию в одном из прошлогодних номеров «Информатики» [4]). В настоящее время благодаря успехам в технологии производства миниатюрных электронных схем сформулированный тезис не имеет столь очевидных (в прямом смысле этого слова!) доказательств, но, тем не менее, своей актуальности не утратил.
Бит слишком маленькая единица информации, чтобы быть достаточной для представления практически полезных данных. Известно, например, что для сохранения одного символа требуется 8 бит, стандартного целого числа – 16, а разрядность целочисленных данных в современных процессорах достигла 32 бит. Следовательно, обеспечивать доступ к каждому отдельному биту памяти едва ли нецелесообразно. Начиная с третьего поколения, в ЭВМ фактически сложился стандарт организации памяти, при котором минимальной считываемой порцией информации является 1 байт [1]. Кроме того, для работы с более крупными данными современные процессоры способны одновременно считывать несколько байт, начиная с заданного (как правило, два или четыре).
Итак, минимальной единицей обмена информацией с памятью в современных компьютерах является 1 байт. Каждый байт имеет свой идентификационный номер, по которому к нему можно обращаться – его принято называть адресом. Адреса соседних байтов отличаются на единицу, зато для двух 32-разрядных чисел, хранящихся в памяти «друг за другом», эта разница по понятным причинам равняется четырем. Практически при обращении к памяти задается адрес начального байта и их требуемое количество (см. 3.3 и 3.2 соответственно).
3.2. Задание размера данных в команде
В семействе процессоров Intel количество считываемых или записываемых байт определяется кодом машинной инструкции [2]. Учитывая, что первые представители этого семейства имели разрядность 16, и лишь начиная с модели 80386 перешли к 32 разрядам, система задания требуемого количества байт выглядит немного запутано. Так, коды команд обращения к байту или слову (вполне естественным образом) отличаются одним битом. Например, байтовая команда MOV AL,1 имеет код B0 01, а двухбайтовая MOV AX,1 кодируется B8 01 00 (длина команды увеличилась из-за размера константы!); легко убедиться, что коды операций B0 и B8 действительно имеют отличие в единственном бите. Что касается четырехбайтовой команды MOV EAX,1, то код ее операции абсолютно такой же, как и у двухбайтовой команды (только константа 1 еще «длиннее» – 4 байта). Оказывается (см. детальную техническую литературу [5] и [6]), что две эти одинаковые по кодам команды процессор различает по установленному режиму: при обработке 32-разрядного участка памяти константа заносится в полный регистр EAX, а 16-разрядного – в его младшую половину AX. Для изменения «режима по умолчанию» служит специальный префиксный код (так называемый префикс переключения разрядности слова, равный 66h), который для следующей за ним инструкции изменяет стандартный режим на противоположный [3]. В результате при работе в 16-разрядном сегменте [4] код 66 B8 01 00 00 00 реализует именно 32-разрядную операцию записи в EAX единицы.
Примечание. Не пытайтесь проверить данное утверждение путем ввода в Debug команды MOV EAX,1 – к сожалению, отладчик «не понимает» мнемоник, содержащих расширенные регистры! (Подробнее об использовании 32-битных операций в Debug см. 3.3.2)
Таким образом, мы видим, что разрядность команды определяется ее кодом (и, может быть, некоторыми «внешними» по отношению к программе факторами). Полученный вывод позволяет нам в дальнейшем ограничиться рассмотрением методов адресации для данных какой-либо фиксированной длины: для остальных достаточно будет просто написать другой код операции.
3.3. Задание адреса данных в команде
В предыдущем разделе было показано, что для понимания методов адресации достаточно рассмотреть способы задания начального адреса при фиксированной длине данных. Поэтому в дальнейшем мы везде будем полагать, что данные имеют двухбайтовый размер. Для упрощения понимания идей адресации в большинстве примеров ограничимся также одной (самой простой!) инструкцией переписи данных, которая имеет мнемоническое обозначение MOV. Подчеркнем, что принятые допущения нисколько не ограничат общности наших знаний по описываемому вопросу.
Итак, перейдем к рассмотрению основных принципов обращения к данным, принятых в компьютерах семейства IBM PC на базе процессоров фирмы Intel.
3.3.1. Адресация простых данных
Под простыми данными принято понимать такие, которые хранят в себе только одно значение, например, целое число. Сложные данные, напротив, включают в себя несколько значений, причем даже не обязательно одного типа [5]; простейшим примером «однородных» сложных данных является массив, о котором мы будем говорить позднее. Не следует путать сложные структуры, состоящие из нескольких более простых значений, в частности из набора целых чисел, с простыми данными, занимающими в памяти нескольких байт, например, с отдельно взятым 32-разрядным целым числом.
Будем пока рассматривать адресацию простых данных. Как выбрано выше, это будут целые 16-разрядные числа.
Простейшие и очень часто используемые инструкции обработки данных, которые выполняются в регистрах микропроцессора, настолько естественны, что легко понимаются на интуитивном уровне. В частности, речь идет о случаях, когда в регистр заносится копия содержимого другого регистра (MOV AX,BX) или константа (MOV AX,30). Тем не менее, с теоретической точки зрения это уже простейшие методы адресации данных, которые для процессоров семейства Intel принято называть регистровой и непосредственной адресацией соответственно [5-9]. Полный перечень методов адресации процессоров Intel приводится в приложении в табл. 1.
Чуть более сложным является случай, когда данные извлекаются из конкретной ячейки памяти, например, MOV AX,[30]; такой метод получил название прямой адресации. Приведенная в качестве примера команда считывает из памяти два байта начиная с адреса 30 и помещает их в 16-разрядный регистр AX. Обязательно обратите внимание на наличие в записи квадратных скобок, которые всегда появляются при ссылке на содержимое памяти.
Подобно тому, как заключение в квадратные скобки константы приводит нас к появлению прямой адресации, аналогичный прием для регистра (например, MOV AX,[BX]) также порождает новый (и очень важный!) метод адресации – косвенный регистровый. Его суть заключается в том, что содержимое регистра рассматривается не как данные, а как адрес памяти, где эти данные расположены.
Для понимания сущности косвенной адресации можно рассмотреть следующую аналогию: при подготовке к экзамену ученик открывает свой конспект по требуемой теме, а там вместо текста для ответа видит запись: «материал по этому вопросу прочитать в § 25». Иными словами, вместо готовой информации дается ссылка на нее.
Или еще одна аналогия из книги [10]: «косвенная адресация похожа на операцию "для передачи (кому-то)", выполняемую почтовой службой США, когда указанный адрес не является реальным адресом получателя, а является адресом друга или родственника».
Чтобы закрепить четыре изученных метода адресации, рассмотрим несложный пример, который складывает два целых числа с адресами 200 и 204. Его выполнение зафиксировано в протоколе 1 и состоит из нескольких действий: ввод программы (команда a) и ее вывод для контроля набора (u); ввод (e200) и вывод чисел (d200); контроль состояния регистров до выполнения программы (r); пошаговое выполнение четырех команд с выводом значений регистров после каждого шага (t4).
При оформлении протокола приняты те же правила, что и в предыдущих выпусках. Подчеркнута информация, на которую при анализе необходимо обратить особое внимание.
Мы надеемся, читатели без труда самостоятельно разберут приводимый протокол 1 и повторят соответствующий диалог в Debug. Не забудьте только о цели эксперимента – поработать с четырьмя различными способами адресации. Поэтому при анализе программы обязательно обратите внимание на то, какие методы использованы в каждой из команд.
Протокол 1
-a 1423:0100 mov ax,[204] 1423:0103 mov bx,200 1423:0106 mov cx,[bx] 1423:0108 add ax,cx 1423:010A -u 1423:0100 A10402 MOV AX,[0204] 1423:0103 BB0002 MOV BX,0200 1423:0106 8B0F MOV CX,[BX] 1423:0108 01C8 ADD AX,CX 1423:010A 0000 ADD [BX+SI],AL ... -e200 5 0 0 0 3 0 -d200 1423:0200 05 00 00 00 03 00 00 00-00 00 00 00 00 00 00 00 ................ ... -r AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0100 NV UP EI PL NZ NA PO NC 1423:0100 A10402 MOV AX,[0204] DS:0204=0003 -t4 AX=0003 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0103 NV UP EI PL NZ NA PO NC 1423:0103 BB0002 MOV BX,0200 AX=0003 BX=0200 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0106 NV UP EI PL NZ NA PO NC 1423:0106 8B0F MOV CX,[BX] DS:0200=0005 AX=0003 BX=0200 CX=0005 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0108 NV UP EI PL NZ NA PO NC 1423:0108 01C8 ADD AX,CX AX=0008 BX=0200 CX=0005 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=010A NV UP EI PL NZ NA PO NC 1423:010A 0000 ADD [BX+SI],AL DS:0200=05 |
Примечание. В очередной раз напоминаем, что по принятому в IBM PC соглашению байты данных хранятся в памяти «задом наперед», т.е. байты 05 00 следует расшифровывать как 0005.
Задания для самостоятельной работы
- Попробуйте модифицировать решение, приведенное в протоколе 1, так чтобы доступ к обеим ячейкам 200 и 204 осуществлялся с помощью косвенной адресации через регистр BX. Используйте возможность сложения значения первого адреса 200 с константой 4.
- Придумайте и реализуйте в Debug свою программу, аналогичную протоколу 1.
3.3.2. Адресация одномерных массивов данных
Рассмотрим теперь более сложную ситуацию, когда однотипные данные (в нашем случае 16-битовые целые) последовательно хранятся в памяти в виде массива. В этом случае имеет место заполнение памяти, изображенное на рис. 1.
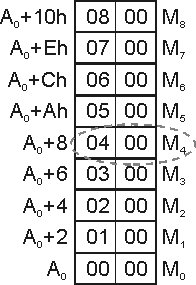
Рис. 1. Организация памяти в виде одномерного массива
Как отчетливо видно из рис. 1, адрес начального байта любого числа легко вычислить по формуле:
Ai = A0 + Di = A0 + 2i;
Обязательно обратите внимание на тот факт, что нумерацию в массиве удобно начинать с нуля: именно в этом случае расчетная формула выглядит наиболее просто. Простота объясняется тем, что фактически для адресации необходимого элемента приходится вычислять объем памяти, занятый всеми предшествующими ему элементами. Таким образом, например, пятому элементу удобнее всего ставить в соответствие номер 4, тогда первому, соответственно 0 (т.е. ему «ничего не предшествует»).
В языках программирования высокого уровня для удобства человека индексы часто все-таки начинают с единицы. В наиболее развитых версиях языка BASIC даже предусмотрен специальный оператор OPTION BASE, который позволяет устанавливать начальное значение индексов массива 0 или 1 (по умолчанию всегда действует 0). В случае, когда индексы начинаются не с 0, а с 1, при вычислении смещения Di следует вместо переменной i написать i–1.
Мы в наших сегодняшних экспериментах ради простоты реализации везде будем начинать отсчет индексов с нуля.
Итак, пусть в памяти, начиная с адреса 200h, располагается массив из 9 двухбайтовых целых чисел, который изображен на рис. 1. Значения чисел, разумеется, можно было задать произвольно, но для удобства проверки правильности работы программ мы занесем в элементы массива их индексы от 0 до 8.
Поставим задачу найти в массиве и извлечь в регистр AX пятый элемент (на рис. 1 он обведен пунктиром; как вы, конечно, поняли из предыдущих рассуждений, этот элемент имеет номер 4).
Для доступа к элементам массива в процессорах фирмы Intel предусмотрен большой ассортимент методов адресации (см. способы 5-11 в табл. 1 приложения). Доступ к массивам основывается на двух методах – базовом и индексном, остальные, как видно из названий, являются их модификациями. О весьма тонком отличии между базовым и индексным методами мы поговорим позднее, а пока познакомимся с индексным способом адресации.
Для хранения индексов в рассматриваемом семействе процессоров предусмотрены специальные индексные регистры SI и DI [6]. Хранящееся в любом из них значение индекса может автоматически складываться с начальным адресом массива, который должен быть указан явным образом в виде константы. Запись 200[SI], например, означает, что при обращении к памяти будет выбран адрес, равный сумме начального адреса массива 200 и индексного смещения, находящегося в данный момент в регистре SI. Подчеркнем, что величина смещения не есть значение индекса: в нашем примере она вдвое превышает последнее, поскольку каждое число занимает 2 байта. Вместо умножения на 2 хорошие программисты, как правило, используют сдвиг на один бит влево; в частности, в нашей программе второй командой стоит SHL SI,1, что как раз и обеспечивает требуемый сдвиг влево (по-английски SHift Left).
Примечание. Сдвиг влево формально эквивалентен приписыванию после числа дополнительного нуля. В повседневной десятичной системе это приводит к увеличению значения в 10 раз (из 12 получается 120!), а в двоичной, соответственно, вдвое.
Приведенного объяснения вполне достаточно чтобы понять работу нашей несложной программы, которая состоит из трех машинных инструкций и описывается в протоколе 2.
Протокол 2
-a 1423:0100 mov si,4 1423:0103 shl si,1 1423:0105 mov ax,200[si] 1423:0109 -u 1423:0100 BE0400 MOV SI,0004 1423:0103 D1E6 SHL SI,1 1423:0105 8B840002 MOV AX,[SI+0200] 1423:0109 0000 ADD [BX+SI],AL ... -e200 0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 -d200 1423:0200 00 00 01 00 02 00 03 00-04 00 05 00 06 00 07 00 ................ 1423:0210 08 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................ ... -t3 AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0004 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0103 NV UP EI PL NZ NA PO NC 1423:0103 D1E6 SHL SI,1 AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0008 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0105 NV UP EI PL NZ AC PO NC 1423:0105 8B840002 MOV AX,[SI+0200] DS:0208=0004 AX=0004 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0008 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0109 NV UP EI PL NZ AC PO NC 1423:0109 0000 ADD [BX+SI],AL DS:0008=1D |
При разборе протокола 2 непременно обратите внимание на следующие детали (соответствующие места в тексте, как обычно, подчеркнуты).
- Индексный операнд 200[SI] Debug расшифровывает «по-своему»: [SI+200].
- Сдвиг влево преобразует значение SI из 4 в 8, т.е действительно удваивает.
- В случае, когда выводимая на экран команда работает с памятью, Debug вычисляет адрес данных с учетом текущего значения регистров (в нашем случае SI) и выводит соответствующее содержимое справа от ассемблерного представления инструкции.
Вот мы и научились пользоваться индексной адресацией.
Внимательное изучение табл. 1 приложения показывает, что в ходе некоторых методов адресации процессор самостоятельно способен умножать индекс на размер данных. В частности, вас должен был заинтересовать масштабированный индексный метод адресации (строка 7 в табл.1), хорошо подходящий к нашей задаче. Главная проблема применения выбранного метода заключается в том, что он работает только в 32-битном режиме и, следовательно, с расширенными регистрами, а их-то Debug как раз и не поддерживает. Трудность, к счастью, состоит не в том, что при работе с Debug нельзя использовать 32-разрядные инструкции, а в том, что их не удается ввести напрямую. В связи с этим предлагаю воспользоваться «обходным» путем: предварительно узнав коды необходимых инструкций, введем их в память как набор байтов.
Учитывая автоматизацию умножения на 2, наша небольшая экспериментальная программа сократиться до двух команд, которым соответствуют следующие шестнадцатеричные коды:
| команда | код |
|---|---|
| mov esi,4 | 66 BE 04 00 00 00 |
| mov ax,200[esi*2] | 67 8B 84 36 00 02 00 00 |
Для получения кодов инструкций я воспользовался программой Flat Assembler (автор Tomasz Grysztar) [11].
Обратим внимание читателей на то, что 66 и 67 это префиксы, переводящие данную команду из 16-разрядного в 32-разрядный режим выполнения, причем первый влияет на размер данных (число 4 заносится в 32-разрядный регистр ESI), а второй – на длину адреса, что, собственно, и позволяет применять изучаемый нами сейчас масштабированный индексный метод адресации.
Дальнейшие действия уже понятны из протокола 3. Подчеркнем, что он предполагается продолжением предыдущего эксперимента по поискам пятого элемента массива, поэтому последний заново вводить не требуется. Зато придется очистить регистр AX и «сбросить» на начало программы счетчик команд IP (см. в протоколе команды rax и rip).
Протокол 3 (продолжение протокола 2)
-a100 1423:0100 db 66 be 4 0 0 0 1423:0106 db 67 8b 84 36 0 2 0 0 1423:010E -u100 1423:0100 66 DB 66 1423:0101 BE0400 MOV SI,0004 1423:0104 0000 ADD [BX+SI],AL 1423:0106 67 DB 67 1423:0107 8B843600 MOV AX,[SI+0036] 1423:010B 0200 ADD AL,[BX+SI] 1423:010D 0000 ADD [BX+SI],AL ... -rax AX 0004 :0 -rip IP 0109 :100 -r AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0008 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0100 NV UP EI PL NZ AC PO NC 1423:0100 66 DB 66 -t2 AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0004 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0106 NV UP EI PL NZ AC PO NC 1423:0106 67 DB 67 AX=0004 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0004 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=010E NV UP EI PL NZ AC PO NC 1423:010E 0000 ADD [BX+SI],AL DS:0004=00 |
В результате оказывается, что хотя Debug и не способен вводить и правильно выводить 32-разрядные команды, те прекрасно выполняются под отладчиком даже в режиме трассировки (анализ содержимого счетчика команд IP показывает, что сборка байтов в команды происходит абсолютно корректно).
Остается разобрать уже упоминавшийся ранее базовый метод адресации. Его суть состоит в том, что адрес данных получается в результате суммирования содержимого базового регистра (BX или BP) с некоторой константой, например, [BX+30]. Это, на первый взгляд, мало чем отличается от изученного нами подробно индексирования, когда адрес также являлся суммой содержимого регистра и константы. И, тем не менее, некоторое тонкое отличие все-таки есть.
Согласно общей теории адресации [1, 12] дело обстоит следующим образом. Как мы уже знаем, адрес элемента массива является суммой двух слагаемых – A0 и Di. Так вот, когда A0 помещается в виде константы команду, а – Di в регистр, то адресация называется индексной (в регистре находится индекс, что, кстати, подчеркивается записью 200[SI]), а при обратном размещении слагаемых (в регистре тогда будет база, т.е. A0) – базовой. У процессоров с универсальными регистрами, допускающими любые методы адресации, отличие чисто смысловое; в тексте программы на ассемблере оно еще заметно по способу записи, но на уровне машинных кодов разница между индексной и базовой адресацией весьма условна [7] (в обоих случаях адрес есть сумма содержимого указанного регистра и константы!)
Что касается процессора Intel, то у него регистры неравноценны. В частности, регистры BP и BX называются базовыми, а SI и DI – индексными, отсюда адресация по BP и BX «обречена» быть базовой, а по SI и DI – индексной. Мы видим, что терминология строится на принципиально другой основе, нежели в теории методов адресации, что дополнительно запутывает и без того нетривиальную классификацию.
Эксперименты с Debug подтверждают изложенную выше точку зрения следующим весьма наглядным образом. Согласно принятым в языке ассемблер правилам, индексная адресация записывается в виде 200[SI], а базовая – [BP+200]. Тем не менее, отладчик кроме стандартного 200[SI] нормально воспринимает набор [SI+200], более того, как мы видели в протоколе 2, при выводе на экран он использует именно последнюю (базовую!) форму записи. Наоборот, вместо базовой формы [BP+200], можно смело вводить индексную 200[BP] с тем же самым результатом. С точки зрения правил ассемблера путаница полная!
Задания для самостоятельной работы
- В табл.1 приложения найдите в последнем столбце в строках 5, 6, 8 и 10 разнообразные допустимые варианты записи индексного и базового методов адресации. (Заметим, что в таблице приведены не все, а лишь сколько-нибудь логичные варианты; на практике вы можете набирать и совсем экзотические выражения типа [SI]30[BX], и Debug послушно преобразует их в осмысленную сумму.) Введите несколько форм записи одной и той же команды и убедитесь в тождественности кодов, которые Debug занесет в память.
- Опробуйте базовую адресацию по аналогии с тем, как это делалось в протоколе 2.
- В программе из протокола 3 команду mov esi,4 замените на mov esi,4000000 с кодом 66 BE 00 00 00 04. Убедитесь, что данная команда, выводящая адрес данных за пределы 64 Кб сегмента, вызывает срабатывание защиты памяти и принудительное (без всякого предупреждения!) завершение сеанса Debug.
3.3.3. Адресация двумерных массивов данных
Перейдем теперь к рассмотрению размещения в памяти двумерных массивов и способов доступа к их отдельным элементам. Типичная картина расположения в памяти элементов массива 3x3 приведена на рис. 2; отдельные строки на рисунке для наглядности сдвинуты.
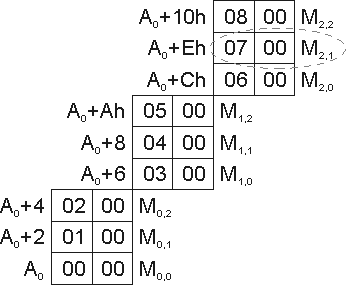
Рис. 2. Организация памяти в виде двумерного массива
Как утверждается в [13], «за исключением языка Fortran, все языки хранят двумерные массивы как последовательность строк. ... Такое размещение вполне естественно, поскольку сохраняет идентичность двумерного массива и массива массивов.»
Для доступа к фиксированному элементу массива с текущими значениями индексов i и j необходимо, по сравнению со случаем одномерного массива, добавить еще слагаемое, учитывающее полный размер всех предшествующих строк (строки опять же удобнее нумеровать с нуля!) В итоге расчетная формула для нашего экспериментального массива с i = 0, 1, 2 и j = 0, 1, 2 приобретет вид
(число 6 получено как произведение числа элементов в строке на размер каждого из них).
Для индексирования нам теперь уже потребуется два регистра, скажем BX и SI (один базовый, другой индексный). Применив базово-индексный метод адресации со смещением, получим программу, реализация которой дается в протоколе 4. Как не без иронии заметил в своей книге [13] Бен-Ари, «Вы, возможно, удивитесь, узнав, что для каждого доступа к массиву нужно столько команд!»
Протокол 4
-a 1423:0100 mov bl,2 1423:0102 mov si,1 1423:0105 mov al,6 1423:0107 mul bl 1423:0109 mov bx,ax 1423:010B shl si,1 1423:010D mov ax,200[bx][si] 1423:0111 -u 1423:0100 B302 MOV BL,02 1423:0102 BE0100 MOV SI,0001 1423:0105 B006 MOV AL,06 1423:0107 F6E3 MUL BL 1423:0109 89C3 MOV BX,AX 1423:010B D1E6 SHL SI,1 1423:010D 8B800002 MOV AX,[BX+SI+0200] 1423:0111 0000 ADD [BX+SI],AL ... -e200 0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 -d200 1423:0200 00 00 01 00 02 00 03 00-04 00 05 00 06 00 07 00 ................ 1423:0210 08 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................ ... -t5 AX=0000 BX=0002 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0102 NV UP EI PL NZ NA PO NC 1423:0102 BE0100 MOV SI,0001 AX=0000 BX=0002 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0001 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0105 NV UP EI PL NZ NA PO NC 1423:0105 B006 MOV AL,06 AX=0006 BX=0002 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0001 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0107 NV UP EI PL NZ NA PO NC 1423:0107 F6E3 MUL BL AX=000C BX=0002 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0001 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0109 NV UP EI PL NZ NA PO NC 1423:0109 89C3 MOV BX,AX AX=000C BX=000C CX=0000 DX=0000 SP=FFEE BP=0000 SI=0001 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=010B NV UP EI PL NZ NA PO NC 1423:010B D1E6 SHL SI,1 -t2 AX=000C BX=000C CX=0000 DX=0000 SP=FFEE BP=0000 SI=0002 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=010D NV UP EI PL NZ AC PO NC 1423:010D 8B800002 MOV AX,[BX+SI+0200] DS:020E=0007 AX=0007 BX=000C CX=0000 DX=0000 SP=FFEE BP=0000 SI=0002 DI=0000 DS=1423 ES=1423 SS=1423 CS=1423 IP=0111 NV UP EI PL NZ AC PO NC 1423:0111 0000 ADD [BX+SI],AL DS:000E=8A |
Особенно длинно выглядит умножение строкового индекса i на 6: мало того, что нельзя умножить на константу и ее приходится отдельной командой помещать в регистр AL [8], но еще дополнительно требуется возвращать произведение из AX обратно в BX.
Примечание. Важно подчеркнуть, что описанный в эксперименте способ вычисления адреса используется только в том случае, когда значения i и j заранее неизвестны и в ходе исполнения берутся из переменных. Если же в тексте программы написан элемент с конкретными индексами, например, M1,1, то современный компилятор немедленно определяет адрес этого элемента в памяти и генерирует всего одну команду с прямой адресацией, в нашем примере MOV AX,[208].
Поскольку порядок проведения эксперимента с двумерным массивом существенно ничем не отличается от описанного в предыдущем разделе, опустим все комментарии.
Задания для самостоятельной работы
- Изменив значения констант в первых двух командах, убедитесь в правильности получения элемента массива с заданными вами индексами. Отдельно проанализируйте случаи с неправильно заданными индексами, например, для M1,4 и M4,1; подумайте, какой из них опаснее.
- Используя нижеследующую таблицу с кодами программы, которая реализует 32-разрядный метод адресации с масштабированием (в ней 16-разрядные команды, выделенные жирным шрифтом можно набирать на ассемблере), введите и исполните ее в Debug.
Ход реализации эксперимента аналогичен приведенному в протоколе 3.
команда код mov ebx,2 66 BB 02 00 00 00 mov esi,1 66 BE 01 00 00 00 mov al,6 B0 06 mul bl F6 E3 mov bx,ax 89 C3 mov ax,[ebx+esi*2+200h] 67 8B 84 73 00 02 00 00 - Напишите и реализуйте в Debug программу суммирования элементов массива. Сможете ли вы ее написать так, чтобы она оказалась пригодной и для одномерного массива?
3.4. Несколько слов о сегментной адресации и ее роли
В компьютерах IBM PC существует историческая особенность адресации к данным в 16-разрядном режиме. При создании самых первых, тогда еще 16-разрядных моделей, конструкторы отчетливо понимали необходимость расширения адресного пространства. Дело в том, что с помощью двухбайтового регистра можно непосредственно адресовать только 216 / 210 = 26 = 64 Кб памяти; именно такой объем в основном и использовался в микрокомпьютерах до IBM PC. Для преодоления этого ограничения инженеры применили весьма специфическое решение – формировать 20-разрядный адрес путем сложения с дополнительным сегментным регистром, причем значение последнего перед сложением сдвигалось влево на 4 разряда (младшие четыре при этом всегда заполнялись нулями, так что получаемое сегментное значение по-прежнему содержало только 16 «значащих» бит). В результате разрядность итогового адреса стала 16+4=20 бит. Величина сдвига была выбрана во многом произвольно, видимо так, чтобы получить возможность установить ОЗУ объемом 640 Кб, т.е. увеличив его на порядок. Говорят, что в это время Билл Гейтс сделал неосторожное заявление о том, что такого объема хватит на долгие времена...
Особенность предложенного метода адресации состоит в том, что если зафиксировать значение сегментной добавки, то адресовать можно по-прежнему только некоторый сегмент памяти размером все те же 64 К. Тем не менее, таких сегментов в ОЗУ можно сформировать много. Кроме того, программист в состоянии менять значения сегментных регистров с помощью весьма разнообразных инструкций процессора, тем самым элементарно переходя от одного сегмента памяти к другому.
В одной из своих книг [2] Питер Нортон метко назвал сегментный способ словом «клудж» (по-английски kludge – приспособление для временного устранения проблемы). С появлением 32-разрядных процессоров (начиная с Intel 80386) 20-разрядная хитрость с сегментами стала абсолютной ненужной, но из-за проводимой фирмой Intel политики полной обратной совместимости этот ненужный «рудимент» жив до сих пор.
Именно по причине постепенного отмирания данного метода адресации, а также потому, что кроме IBM PC он нигде больше не применялся, мы не будем его изучать. Отметим только одну особенность, которая объяснит, почему многие числа в приводимых в наших статьях протоколах выделены наклонным шрифтом (напомним, что так помечен текст протокола, который при проведении экспериментов на вашем компьютере, скорее всего, будет другим).
В процессорах Intel имеется несколько сегментных регистров: CS для определения кодового (программного) сегмента, DS – для сегмента данных программы, SS – для стека; дополнительные сегментные регистры ES, FS и GS предназначены для создания структур данных, причем из них только ES используется в конкретных командах и отображается в Debug (см. любой протокол). Обычно прикладные программы, особенно несложные, не меняют значения сегментных регистров и даже не задают их начальные значения, а получают их «готовыми» от операционной системы. В этом есть глубокий смысл: операционная система, занося в сегментные регистры некоторые значения, тем самым выделяет программе некоторый сегмент памяти, за который без необходимости выходить не стоит. Нетрудно видеть, что для простоты все сегментные регистры устанавливаются на одно и то же значение (во всех моих протоколах стоит число 1423), что совмещает все сегменты в единый сегмент памяти. Для начинающих программистов это весьма удобное решение.
Наконец, поясним еще одну особенность записи адресов в Debug. При сегментном методе каждый адрес представляется в виде двух чисел, разделенных двоеточием, например, полный адрес экспериментального массива в моем протоколе выглядит как 1423:0200 (у вас первое число, конечно, свое). Число перед двоеточием и есть соответствующее значение сегментного регистра, установленное операционной системой. Поскольку ни в одном из наших экспериментов сегмент не изменялся, в процессе обсуждения на него можно просто не обращать внимания (это тем более удобно, поскольку значения сегментных регистров у нас могут быть разными).
3.5. Как получается физический адрес памяти
После проведения наших экспериментов, мы получили некоторое представление о том, что каждая задача в отведенной ей области памяти может использовать весьма гибкий набор методов адресации. В частности, в наиболее сложных случаях адрес данных получается как сумма трех компонент: базового и индексного регистров с некоторым смещением. Полученное число, которое позволяет нашей программе найти в своем собственном адресном пространстве любые данные, принято называть эффективным адресом. Но действительно ли мы обращаемся к тем адресам памяти, которые получаются после суммирования? Конечно нет, и тому существует глубокая причина, именуемая многозадачностью. Современная операционная система создает каждой запускаемой программе такие условия, как будто она одна находится в памяти, поэтому просто нельзя допустить, чтобы каждая из задач имела возможность напрямую обращаться к реальным физическим адресам. Если такой запрет кажется вам несущественным, попробуйте представить себе, что может произойти, если три разные программы начнут одновременно использовать для хранения своих данных одну и ту же ячейку ОЗУ!
Из предыдущего раздела мы знаем, что в процессорах с системой команд Intel к полученному «внутреннему» адресу данных еще добавляется определенным образом содержимое сегментного регистра. Полученный в результате адрес называют линейным адресом. У самой первой модели процессора (с номером 8086) 20-разрядный линейный адрес был окончательным результатом и непосредственно использовался для выборки данных из физической памяти. Но компьютеры на базе такого процессора были способны обеспечить лишь около 1 Мб памяти и функционирование однозадачной операционной системы, какой являлась MS-DOS.
Чтобы создать техническую базу для многозадачных систем, описанного механизма адресации явно недостаточно. Поэтому в последующих моделях, начиная с 80286 (и особенно с выходом 32-разрядной 80386), появился новый режим работы – защищенный (protected mode); первоначальный однозадачный режим стал называться реальным (real mode). В защищенном режиме адресация усложнилась, зато ее возможности существенно возросли. Для того чтобы получить некоторое представление о новом режиме, обратимся к рис. 3.
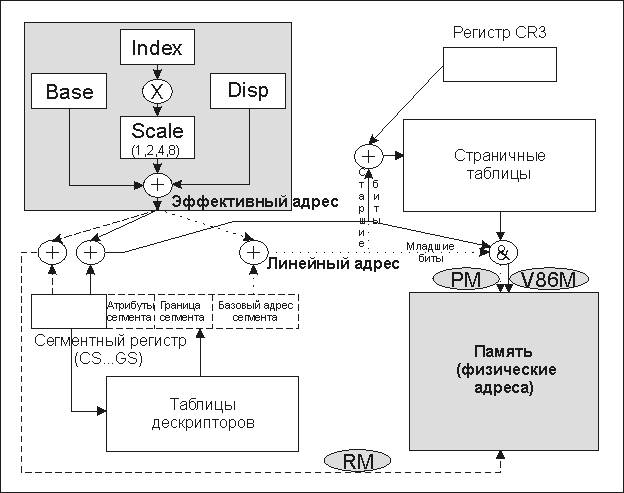
Рис. 3. Механизмы адресации процессоров Intel в различных режимах
В левом верхнем углу рисунка символически изображены механизмы логической адресации, обсуждавшиеся ранее по табл. 1. Эффективный адрес, получающийся в результате, в реальном режиме складывается с содержимым сдвинутого влево сегментного регистра [9] (соответствующая пунктирная линия на рис. 3 подписана RM).
В защищенном режиме значение из сегментного регистра используется не как составляющая адреса, а в качестве индекса специальных так называемых таблиц дескрипторов [10] (см. на рис. 3 ломаную, образованную точками и помеченную PM). Каждый дескриптор содержит информацию о базовом адресе сегмента памяти и его границе (т.е. фактически о размере), а также атрибуты для данной области памяти, такие как уровень защиты доступа, способ задания размера сегмента и некоторые другие технические особенности выделенного участка памяти. Нас сейчас больше всего интересует первый из названных параметров, который, суммируясь (уже без всяких сдвигов!) с эффективным адресом, формирует линейный адрес защищенного режима. Заметим, что при этом аппаратным образом всегда производится проверка допустимости полученного адреса, иначе говоря, осуществляется защита памяти от некорректного доступа.
Рассмотренный сегментный механизм преобразования адресов в защищенном режиме является только первым шагом. Полученный в результате линейный адрес может быть подвергнут страничному преобразованию (данный этап не является обязательным: страничный механизм способен отключаться). Важной чертой страничного преобразования является разделение линейного адреса на две части: младшие 12 бит фиксированы и фактически служат адресом данных внутри страницы. Зато остальные (старшие) биты при помощи специальных таблиц преобразуются, и в результате из линейного адреса, наконец, получается действительный физический адрес памяти (механизм также предусматривает аппаратную защиту при доступе к данным). Именно благодаря страничному механизму в современных компьютерах реализуется виртуальная память, объединяющая ОЗУ и специальный файл его расширения на диске.
Как и сегментный механизм, страничный позволяет пересчитать одинаковые логические (эффективные) адреса, принадлежащие разным задачам, в абсолютно независимые области памяти. В страничном механизме для этой цели предусмотрен контрольный регистр процессора CR3, значение которого обязательно перезагружается при переключении задач; тем самым каждая задача всегда имеет собственные страничные таблицы для преобразования адресов.
Кратко описанный выше процесс преобразования логических адресов конкретной задачи в физические адреса ячеек компьютерной памяти для наиболее полного случая защищенного режима обобщен на рис. 4 (все значения адресов на нем выбраны произвольно).
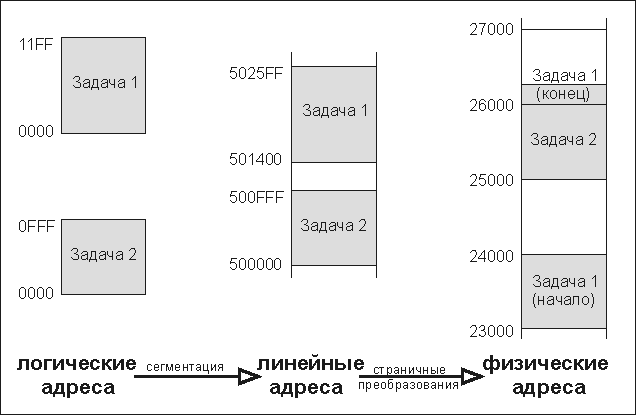
Рис. 4. Преобразование адресов отдельной задачи в физические адреса памяти
Из рис. 4 можно сделать следующие вводы.
- Размер и начальные адреса сегментов произвольны, для страниц они, напротив, фиксированы.
- Логическая адресация внутри отдельных задач произвольна и независима.
- В линейном пространстве каждая задача получает собственный участок (если потребуется, то несколько участков) памяти.
- При страничной переадресации задаче независимо от количества фактически требуемых байт выделяются только фиксированные объемы памяти (кратные длине страниц); страницы одной задачи не обязаны находится в смежных областях памяти.
Примечание. Фрагментация страниц памяти, принадлежащих к одной задаче, имеет такую же природу, как и фрагментация файлов на интенсивно используемом диске, который разбит на отдельные кластеры!
Помимо рассмотренных выше реального и защищенного режимов, в процессорах Intel существует еще один «промежуточный» режим работы – режим виртуального процессора 8086 (virtual mode). Он во многом похож на реальный режим, но, в отличие от последнего, допускает функционирование параллельно выполнению других задач. Строго говоря, в режиме V86 выполняется стандартная защищенная задача – имитатор среды 8086, под управлением которой и запускается та или иная прикладная программа. На языке пользователей Windows монитор V86 принято называть виртуальной DOS-машиной, а выполняемое под ее управлением приложение сеансом MS-DOS. Нетрудно сообразить, что Debug работает именно в таком режиме.
Примечание. Возможности режима V86 шире, чем реального; примером этого, в частности, служит допустимость в нем 32-разрядной адресации, которой мы воспользовались в ходе нашего эксперимента (см. протокол 3).
Особенностью описываемого режима является отсутствие механизма сегментации адресов с помощью таблиц дескрипторов. Как видно из рис. 3, сегментный регистр в V86 используется точно также, как и в реальном режиме, а полученный в результате сложения со сдвигом адрес сразу передается на страничную переадресацию (см. сплошные стрелки на рисунке, помеченные текстом V86M). Благодаря механизму страничной переадресации процессор способен создать несколько виртуальных машин, которые к тому же могут работать параллельно с другими защищенными приложениями.
Особенности формирования адресов в различных режимах процессоров семейства Intel обобщены в табл. 2 приложения, которая в основном базируется на данных [14].
В качестве важного вывода отметим, что прикладному программисту доступны только методы формирования логического адреса; обслуживанием механизмов сегментации и страничной переадресации занимается операционная система. Последняя из соображений безопасности стремится ограничить влияние программ на любые не относящиеся к ним области памяти, «монополизируя» для этой цели все механизмы распределения физической памяти и не допуская к ним прикладные программы. Именно по этой причине, пользуясь Debug в среде Windows, не удастся провести какой-либо эксперимент с сегментацией или страничной переадресацией.
3.6. Сравнение с методами адресации памяти другого процессора
Широкое распространение в нашей стране Intel-совместимых процессоров довольно часто приводит к иллюзии, что все процессоры работают одинаково. Тем не менее, это не совсем верная точка зрения, поскольку различные семейства процессоров могут иметь свои особенности, в том числе весьма специфические.
Поэтому очень кратко для сравнения познакомимся с методами адресации в командах компьютера PDP-11 [10], которые представлены в приложении в табл. 3. В соответствии с целями нашего сопоставления в указанной таблице отражены аналогии с методами адресации IBM PC, по крайней мере, там, где они существуют.
Внимательное изучение табл. 3 позволяет сделать о системе адресации данных следующие обобщающие выводы.
- Названия одних и тех же методов адресации у различных семейств машин чаще всего не совпадают.
- Самые важные (основополагающие) методы адресации у большинства микропроцессоров одинаковы, в частности, регистровая, косвенная регистровая, прямая, непосредственная (в терминологии IBM PC).
- Каждое семейство компьютеров может иметь свои специфические особенности адресации. Например, сегментный способ в IBM или автоинкрементный метод в PDP.
- Семейство PDP имеет более развитую и логичную систему адресации. Например, многие «традиционные» методы (прямая, непосредственная или стековая) получаются здесь как некоторые частные случаи.
К приведенным выше выводам следует дополнить, что PDP-11 по своим возможностям следует рассматривать как некоторый аналог однозадачной модели процессора Intel 8086. Более поздняя машина, предназначенная для многозадачной работы – VAX-11, имеет соответствующие дополнительные возможности: страничная адресация виртуальной памяти; масштабирование адресов данных по количеству байт; прибавление к адресу, полученному согласно табл. 3, содержимого еще одного регистра и некоторые другие [10]. Мы не будем здесь касаться перечисленных деталей.
Литература
- Бруснецов Н.П. Микрокомпьютеры. М.: Наука. Гл. ред. физ.-мат. лит., 1985, 208 с.
- Нортон П., Соухэ Д. Язык ассемблера для IBM PC. М.: Издательство «Компьютер»; Финансы и статистика, 1992, 352 с.
- Заславская О.Ю. Работа с регистрами центрального процессора. Информатика, N 1, 2005, с.39-42
- Еремин Е.А. Устройство ОЗУ. Информатика, 2005, N 23, с.21-26
- Intel Architecture Software Developer’s Manual, Volume 3: System Programming. Intel Corp., 1999
- Гук М. Процессоры Intel: от 8086 до Pentium II. СПб.: Питер, 1997, 224 с.
- Шагурин И.И., Бердышев Е.М. Процессоры семейства Intel P6. Архитектура, программирование, интерфейс. М.: Горячая линия - Телеком, 2000, 248 с.
- Смит Б.Э., Джонсон М.Т. Архитектура и программирование микропроцессора Intel 80386. М.: Конкорд, 1992, 334 с.
- Скэнлон Л. Персональные ЭВМ IBM PC и XT. Программирование на языке ассемблера. М. Радио и связь, 1991, 336 с.
- Лин В. PDP-11 и VAX-11. Архитектура и программирование на языке ассемблера. М.: Радио и связь, 1989, 320 с.
- https://flatassembler.net/
- Информатика в понятиях и терминах / Г.А. Бордовский, В.А. Извозчиков, Ю.В. Исаев, В.В. Морозов; Под ред. В.А. Извозчикова. М.: Просвещение, 1991, 208 с.
- Бен-Ари М. Языки программирования. Практический сравнительный анализ. М.: Мир, 2000, 366 с.
- Ершова Н.Ю., Соловьев А.В. Организация вычислительных систем.
Приложения
Таблица 1. Полная таблица методов адресации процессоров семейства Intel
| Название метода | Вычисление адреса | Операнд | Пример | |
|---|---|---|---|---|
| 1 | регистровая адресация | – | содержимое регистра | mov ax,bx |
| 2 | непосредственная | – | константа в команде | mov ax,30 |
| 3 | прямая | EA=Disp | д.п.а. из команды | mov ax,[30] |
| 4 | косвенная регистровая | EA=Base | д.п.а. из регистра | mov ax,[bx] |
| 5 | базовая | EA=Base+Disp | д.п.а., равному содержимому базового регистра + смещение | mov ax,[bx+30] (или: [bx]+30, 30[bx]) |
| 6 | индексная | EA=Index+Disp | д.п.а., равному содержимому индексного регистра + смещение | mov ax,30[si] (или [si+30]) |
| 7* | масштабированная индексная | EA=Scale*Index+Disp | см.6, но индекс предварительно умножается на масштаб | mov ax,30[esi*2] |
| 8 | базово-индексная | EA=Base+Index | д.п.а., равному сумме двух регистров | mov ax,[bx+si] (или [bx][si]) |
| 9* | масштабированная базово-индексная | EA=Base+ Scale*Index | см.8, но индекс предварительно умножается на масштаб | mov ax,[ebx+esi*2] |
| 10 | базово-индексная со смещением | EA=Base+Index+Disp | д.п.а., равному сумме двух регистров и смещения | mov ax,[bx+si+30] (или: [bx+30][si], [bx][si+30], 30[bx][si]) |
| 11* | масштабированная базово-индексная со смещением | EA=Base+ Scale*Index+ Disp | см.10, но индекс предварительно умножается на масштаб | mov ax,[ebx+esi*2+30] |
| 12** | стековая (неявная адресация) | EA=SP-2 EA=SP |
содержимое регистра содержимое стека |
push ax pop ax |
* – масштабирование индекса возможно только в 32-битном режиме
** – стековый механизм адресации будет рассмотрен отдельно
Обозначения:
EA – эффективный адрес
Disp – смещение (от английского слова displacement)
Base – база
Index – индекс
Scale – масштаб (количество байт в каждом из данных)
Сокращение д.п.а. в столбце «Операнд» означает «данные из памяти по адресу».
Таблица 2. Особенности формирования адресов в различных режимах процессоров семейства Intel
| Характеристика | RM | PM | V86M | SMM |
|---|---|---|---|---|
| Дескрипторные таблицы при сегментации | нет | да | нет | нет |
| Предел сегментов | 64 Кб | из дескриптора | 64 Кб | 4 Гб |
| Размер адреса и данных по умолчанию | 16 бит | из дескриптора | 16 бит | 16 бит |
| Максимальный объем виртуальной памяти | ~ 1 Мб | ~ 64 Тб | ~ 1 Мб | ~ 4 Гб |
| Защита | предела сегментов | да | да | нет |
| Страничная трансляция | нет | да | да | нет |
| Многозадачность | нет | да | да | нет |
SMM – System Management Mode, режим системного управления (используется при переходе системы в режим пониженного энергопотребления)
Таблица 3. Полная таблица методов адресации процессоров семейства PDP
| Название метода | Операнд | Пример | Аналог в IBM PC | |
|---|---|---|---|---|
| 0 | прямая адресация | содержимое регистра | mov R1,R2 | регистровая |
| 1 | косвенная | д.п.а. из регистра | mov (R1),R2 | косвенная регистровая |
| 2 | косвенная с последующим автоувеличением | д.п.а. из регистра; затем регистр увеличивается | mov (R1)+,R2 | отсутствует |
| 3 | двойная косвенная с последующим автоувеличением | д.п.а. из ячейки, на которую показывает регистр; затем регистр увеличивается | mov @(R1)+,R2 | отсутствует |
| 4 | косвенная с предварительным автоуменьшением | регистр уменьшается, затем считываются д.п.а. из регистра | mov –(R1),R2 | отсутствует |
| 5 | двойная косвенная с предварительным автоуменьшением | регистр уменьшается, затем считываются д.п.а. из ячейки, на которую показывает регистр | mov @–(R1),R2 | отсутствует |
| 6 | косвенная с индексацией | д.п.а., равному содержимому регистра + смещение | mov 30(R1),R2 | индексная (базовая) |
| 7 | двойная косвенная с индексацией | д.п.а. из ячейки, на которую показывает содержимое регистра + смещение | mov @30(R1),R2 | отсутствует |
| Важные частные случаи: | ||||
| адресация по программному счетчику R7 (аналог IP в IBM PC) | ||||
| 27 | непосредственная | константа в команде | mov #30,R2 | непосредственная |
| 37 | абсолютная | д.п.а. из команды | mov @#30,R2 | прямая |
| 67 | относительная | д.п.а., равному R7+D | mov D,R2 | отсутствует |
| 77 | относительная косвенная | д.п.а. из ячейки, на которую показывает R7+D | mov @D,R2 | отсутствует |
| адресация по указателю стека R6 (аналог SP в IBM PC) | ||||
| 46 | запись в стек | см. метод 4 | mov R1,–(SP) | push ax |
| 26 | считывание из стека | см. метод 2 | mov (SP)+,R2 | pop bx |
Обозначения:
D – смещение
Сокращение д.п.а. в столбце «Операнд» означает «данные из памяти по адресу».
[1] сказанное ни в коем случае не следует понимать, как невозможность использования информации из отдельного бита: ничто не мешает процессору считать байт целиком, а затем с помощью логических операций выделить и проанализировать содержимое конкретного бита в этом байте
[2] а также зависит от режима работы с памятью, о чем см. далее
[3] хорошей аналогией влияния префикса служит клавиша «F» в инженерных калькуляторах, позволяющая у каждой клавиши иметь вторую функцию
[4] Debug, родившийся в 16-разрядной MS-DOS, работает именно в таком сегменте
[5] вспомните тип record (запись) в Паскале
[6] SI – Source Index (индекс источника данных), DI – Destination Index (индекс назначения для результата)
[7] в частном случае A0 = Di оба метода практически совпадают
[8] в программе для простоты перемножаются два 8-битных числа
[9] полный сегментный регистр состоит из 64 разрядов, но прикладному программисту доступны только старшие 16 (они выделены сплошной линией)
[10] descriptor согласно англо-русскому компьютерному словарю – описатель (описание), паспорт
© Е.А.Еремин, 2007
Публикация:
Еремин Е.А. Как процессор обменивается данными с памятью. "Информатика", 2007, N 20, с.39-43; N 21, с.41-44; N 22, с.41-43; N 23, с.40-44; N 24, с.40-41.
