|



Хранение нечисловых видов информации
ЭВМ первых двух поколений могли обрабатывать только числовую информацию, полностью оправдывая свое название вычислительных машин. Лишь переход к третьему поколению принес изменения: к этому времени уже назрела настоятельная необходимость использования текстов. Следуя ходу исторического развития, мы тоже начнем наше рассмотрение с этого вида информации.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Каждый символ хранится в виде двоичного кода, который является номером символа. Можно сказать, что компьютер имеет собственный алфавит, где весь набор символов строго упорядочен. Количество символов в алфавите также тесно связано с двоичным представлением и у всех ЭВМ равняется 256. Иными словами, каждый символ всегда кодируется 8 битами, т.е. занимает ровно один байт.
Как видите, хранится не начертание буквы, а ее номер. Именно по этому номеру воспроизводится вид символа на экране дисплея или на бумаге. Поскольку алфавиты в различных типах ЭВМ не полностью совпадают, при переносе с одной модели на другую может произойти превращение разумного текста в "абракадабру". Такой эффект иногда получается даже на одной машине в различных программных средах: например, русский текст, набранный в MS DOS, нельзя без специального преобразования прочитать в Windows. Остается утешать себя тем, что задача перекодировки текста из одной кодовой таблицы в другую довольно проста и при наличии программ машина сама великолепно с ней справляется.
Наиболее стабильное положение в алфавитах всех ЭВМ занимают латинские буквы, цифры и некоторые специальные знаки. Это связано с существованием международного стандарта ASCII (American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Русские же буквы не стандартизированы и могут иметь различную кодировку.
Ниже в качестве примера приводится таблица стандартной части алфавита ЭВМ - символы с шестнадцатиричными кодами с 20 до 7F.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 2 | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ |
Пример: код 52 соответствует "R".
Нельзя также пройти мимо еще одного интересного факта: каждый символ текста имеет свой числовой код, но не каждому коду соответствует отображаемый на экране символ. Речь идет о существовании так называемых УПРАВЛЯЮЩИХ КОДОВ, величина которых меньше шестнадцатиричного числа 20 (т.е. 32 в десятичной системе счисления). При получении этих кодов внешние устройства не изображают какого-либо символа, а выполняют те или иные управляющие действия. Так, код 07 вызывает подачу стандартного звукового сигнала, а код 0C - очистку экрана. Особую роль играют коды 0A (перевод строки, обозначаемый часто LF) и 0D (возврат каретки - CR). Первый вызывает перемещение в следующую строку без изменения позиции, а второй - на начало текущей строки. Таким образом, для перехода на начало новой строки требуются оба кода и в любом тексте эта "неразлучная пара" кодов хранится после каждой строки.
Обратим внимание читателя на то, что названия возврат каретки и перевод строки имеют историческое происхождение и связаны с устройством пишущей машинки.
Теперь рассмотрим очень кратко, не вдаваясь в технические подробности, основные принципы хранения в памяти ЭВМ графической информации. В отличии от только что рассмотренного текстового режима дисплея, когда минимальной единицей изображения является символ, при отображении графики картинка строится из отдельных элементов - ПИКСЕЛОВ (от английских слов PICture ELement, означающих "элемент картинки"). Очень часто пиксел совпадает с точкой дисплея, но это совсем необязательно: например, в некоторых видеорежимах 1 пиксел может состоять из 2 или 4 точек экрана.
Каждый пиксел характеризуется цветом. Как и вся остальная информация в ЭВМ, цвет кодируется числом. В зависимости от количества допустимых цветов, число двоичных разрядов на один пиксел будет различным. Так, для черно-белой картинки закодировать цвет точки можно одним битом: 0 - черный, 1 - белый. Для случая 16 цветов требуется уже по 4 разряда на каждую точку, а для 256 цветов - 8, т.е. 1 байт.
Для того, чтобы наглядно представить себе, как хранится в памяти ЭВМ простейшее изображение, рассмотрим для примера белый квадратик на черном фоне размером 4х4. В черно-белом режиме это будет выглядеть наиболее компактно (сначала для наглядности приведен двоичный, а затем шестнадцатиричный вид):
| 1111 | F |
| 1001 | 9 |
| 1001 | 9 |
| 1111 | F |
В режиме 16-цветной графики это же самое изображение потребует памяти в 4 раза больше:
| 1111 1111 1111 1111 | F F F F |
| 1111 0000 0000 1111 | F 0 0 F |
| 1111 0000 0000 1111 | F 0 0 F |
| 1111 1111 1111 1111 | F F F F |
Наконец, при 256 цветах на каждую точку требуется уже по байту и наш квадратик разрастется еще вдвое:
| 11111111 11111111 11111111 11111111 | FF FF FF FF |
| 11111111 00000000 00000000 11111111 | FF 00 00 FF |
| 11111111 00000000 00000000 11111111 | FF 00 00 FF |
| 11111111 11111111 11111111 11111111 | FF FF FF FF |
Обратите внимание на то, что белый цвет, как самый яркий, обычно имеет максимально возможный номер. Поэтому для черно-белого режима он равен 1, для 16-цветного - 15, а для 256 цветов - 255.
Осталось обсудить вопрос, как кодируются промежуточные цвета. Например, вполне естественно со стороны читателя спросить: какой номер имеет, например, красный цвет? К сожалению, методы кодирования цвета даже для одной и той же ЭВМ могут довольно существенно различаться. Причем не только в зависимости от конструкции дисплея, но даже от графического режима, в котором тот в данный момент работает! Более того, соответствие между номерами цветов и их представлением на экране можно переопределять по усмотрению пользователя (это называется изменением палитры). Поэтому давайте ограничимся в качестве примера стандартным 16-цветным набором для наиболее распространенного компьютера IBM PC (по данным [Нортон П. Персональный компьютер фирмы IBM и операционная система MS DOS. М.: Радио и связь, 1992. - 416 с.]):
| 0 - черный | 8 - темно-серый |
| 1 - синий | 9 - ярко-синий |
| 2 - зеленый | A - ярко-зеленый |
| 3 - голубой | B - ярко-голубой |
| 4 - красный | C - ярко-красный |
| 5 - розовый | D - ярко-розовый |
| 6 - коричневый | E - ярко-желтый |
| 7 - серый | F - ярко-белый |
Таким образом, графическая информация, также как числовая и текстовая, в конечном счете заносится в память в виде двоичных чисел.
Несколько забегая вперед, к следующему поколению, рассмотрим дополнительно кодирование звуковой информации (ЭВМ третьего поколения, конечно, еще не умела обрабатывать этот вид информации). Принцип преобразования звукового сигнала в цифровую форму и его последующее воспроизведение показаны на рис.2.
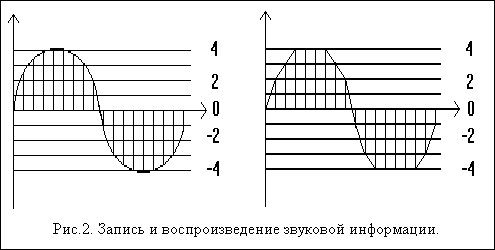
Запись звука происходит следующим образом. Выбирается система равноотстоящих друг от друга уровней напряжения сигнала и каждому из них ставится в соответствие определенный номер. Затем через равные очень небольшие промежутки времени измеряется уровень входного сигнала и определяется, к какому из стандартных уровней он ближе всего подходит; номер найденного уровня и записывается в память в качестве громкости звука в данный момент.
Для высококачественной стереофонической записи используется частота 44000 Гц, т.е. измерение происходит десятки тысяч раз в секунду.
При воспроизведении данные считываются, и с такой же самой, как и при записи, высокой частотой компьютер изменяет интенсивность звука в зависимости от прочитанных номеров уровней. Интересно, что регулировка громкости при таком методе воспроизведения в самом прямом смысле осуществляется с помощью умножения: например, чтобы увеличить громкость вдвое, перед воспроизведением номер уровня необходимо также удвоить.
Таким образом, рассмотрев принципы хранения в ЭВМ различных видов информации, можно сделать важный вывод о том, что все они так или иначе преобразуются в числовую форму и кодируются набором нулей и единиц. Благодаря такой универсальности представления данных, если из памяти наудачу извлечь содержимое какой-нибудь ячейки, то принципиально невозможно определить, какая именно информация там закодирована: текст, число или картинка.
© Е.А.Еремин, 1997
Из книги:
Еремин Е.А. Как работает современный компьютер. - Пермь: изд-во ПРИПИТ, 1997. 176 с.
