|



Что означает термин "Big Endian"?
Память компьютера имеет байтовую организацию, а каждый байт имеет свой номер - адрес. Одного байта чаще всего недостаточно для хранения какой-либо информации (например, согласно старым стандартам под целое число требовалось 2 байта; в современных компьютерах часто необходимы большие значения, поэтому целое число может занимает 4 или даже 8 байт!) Следовательно надо иметь возможность сохранять информацию в нескольких соседних байтах.
Чтобы расположить информацию в нескольких байтах, можно выбрать один из двух способов.
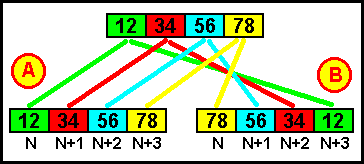
| A. Байт с наибольшей значащей частью ("big-end", в исходном числе он находится слева) сохраняется в память по наименьшему адресу (на рисунке это N). Такой способ принято называть "big-endian" - по-русски говорят "обратное размещение байтов". Попутно заметим, что байт наибольшей значимой частью в компьютерной литературе часто обозначают MSB (Most Significant Byte). | B. Байт с наибольшей значащей частью (слева) сохраняется в память по наибольшему адресу (на рисунке это N+3). Следовательно первым, наоборот, сохраняется байт с наименьшей значащей частью ("little-end", в исходном числе находится справа). Такой способ принято называть "little-endian" - по-русски говорят "прямое размещение байтов". |
|
P.S. По правде говоря, ни в одной из имеющихся у меня книг термины "прямой/обратный порядок" не разъясняются. Мне казалось, что когда в любой программе при отображении содержимого памяти части числа хранятся "задом наперед", вряд ли это будет названо "прямой порядок".
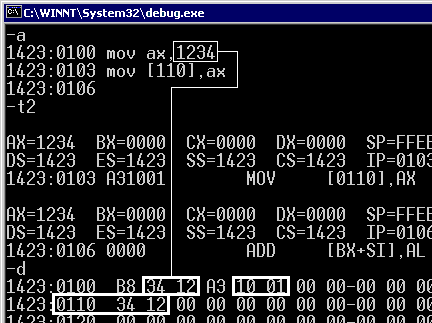 Ан нет, неправ оказался! Это прямой порядок. Видимо, так назвали математики: для них нумерация битов естественнее справа налево (и это действительно удобнее для всех формул!), стало быть (по аналогии) когда младший байт имеет меньший номер - это более нормально, чем наоборот. Тогда получается, что в IBM PC прямой порядок байтов. |
Из описанного выше следует, что различие состоит в том, "с какого конца" (end) необходимо начинать сохранять многобайтовое данное. Вот отсюда-то и происходит сам образный термин. Он был предложен в одной из статей, посвященной рассматриваемому вопросу со ссылкой на книгу Джонатана Свифта "Приключения Гулливера". Как Вы, наверно, помните, в Лилипутии ради обсуждения проблемы с какого конца - тупого или острого (по-английски "big side" или "little side") разбивать яйцо были созданы две непримиримые политические партии. Во многом компьютерные дебаты по обсуждению big-/little-endian выгдядят аналогично.
Можно, правда, аргументировать, что "little-endian"-архитектура удобнее по следующему соображению. При этом способе представления целое число, занимающее машинное слово с адресом n, и байт с тем же адресом содержат одно и то же значение (конечно, если оно не превышает 255). Напротив, в случае "big-endian" это не так: например, если целое число с адресом n содержит число 17, то старший байт с адресом n очевидным образом хранит 0; или если целое число имеет отрицательное значение -77, то для него байт с адресом n содержит отрицательное значение -1. При небрежном программировании это может стать источником ошибок.
С другой стороны, многие компьютерные протоколы исторически ориентируются на "big-endian", например, все протоколы сети Internet передают данные в этом формате. Поэтому на машинах с архитектурой "little-endian" приходится переставлять байты внутри слова перед отправкой IP-пакета в сеть и при получении IP-пакета из сети. По моему мнению, ни одна из архитектур не имеет бесспорных преимуществ.
Распространенные у нас компьютеры с Intel-совместимыми процессорами используют архитектуру "little-endian". Аналогичный способ использовался также в машинах PDP-11 и VAX. Таким образом, в нашей стране это наиболее известный метод хранения данных. Тем не менее существовали и до сих пор существуют "big-endian" компьютеры, например, IBM 370, Motorola 68000 (семейство компьютеров "Apple"), Sun Sparc и многие RISC-процессоры. А вот система PowerPC "понимает" сразу оба формата данных и ее иногда называют "bi-endian".
Оба рассмотренных подхода теоретически можно применить и к порядку сохранения битов внутри байта. По счастью, мне не удалось найти конкретных ссылок на системы с "little-endian" порядком битов. Возможно, это связано с тем, что все биты в байте начали использоваться одновременно, сразу, а данные от 8 до 64 разрядов наращивались постепенно, в том числе и разными путями.
Следует иметь ввиду, что существенным является не столько то, как компьютерная система хранит данные "внутри себя" (в конце концов это ее внутренне дело), а то, как она их сохраняет "снаружи" в файлах. Это с практической точки зрения гораздо важнее.
В качестве примера представим, что текст "UNIX" в качестве двух 2-байтовых слов сохранен "big-endian" системой. Тогда "little-endian" система по своим правилам расшифрует его как "NUXI", переставив буквы в каждом из машинных слов. Это недоразумение, также связанное с обсуждаемым вопросом, иногда называют "проблемой NUXI". Аналогичные трудности могут возникать при сохранении графических изображений, поскольку цвета в современных компьютерах также кодируются многобайтовыми числами. Так, например, файлы программы Adobe Photoshop и широко распространенный "фотографический" формат JPEG используют схему "big-endian", а не менее распространенные файлы GIF и BMP - "little-endian" (более подробный перечень файлов см., например, здесь).
В современном "внеплатформенном" (не предназначенном для какого-то конкретного компьютера) языке Java все данные также хранятся по способу "big-endian". А в языке ADA 95 программисту разрешается задавать режим хранения многобайтовых данных.
| Я считаю, что для учебных моделей понятнее и нагляднее является метод "big-endian" (см. модели "Нейман" и MMIX). |
- Нотон П., Шилдт Г. Полный справочник по Java. - К.: Диалектика, 1997. - 592 с. (см. стр.36)
- Бен-Ари М. Языки программирования. Практический сравнительный анализ. - М.: Мир, 2000. - 366 с. (см. стр.95)
- Костельцев А.В. BIG-ENDIAN & LITTLE-ENDIAN (на русском языке)
- Webopedia - Интернет-энциклопедия (на английском языке)
- Denis Howe. FOLDOC (Free On-Line Dictionary Of Computing) (на английском языке)
- William T. Verts. An Essay on Endian Order (на английском языке)
- Roedy Green. Big/Little Endian in Java (на английском языке)
© Е.А.Еремин, 2002. Обновление - 2008.
